Robots.txt
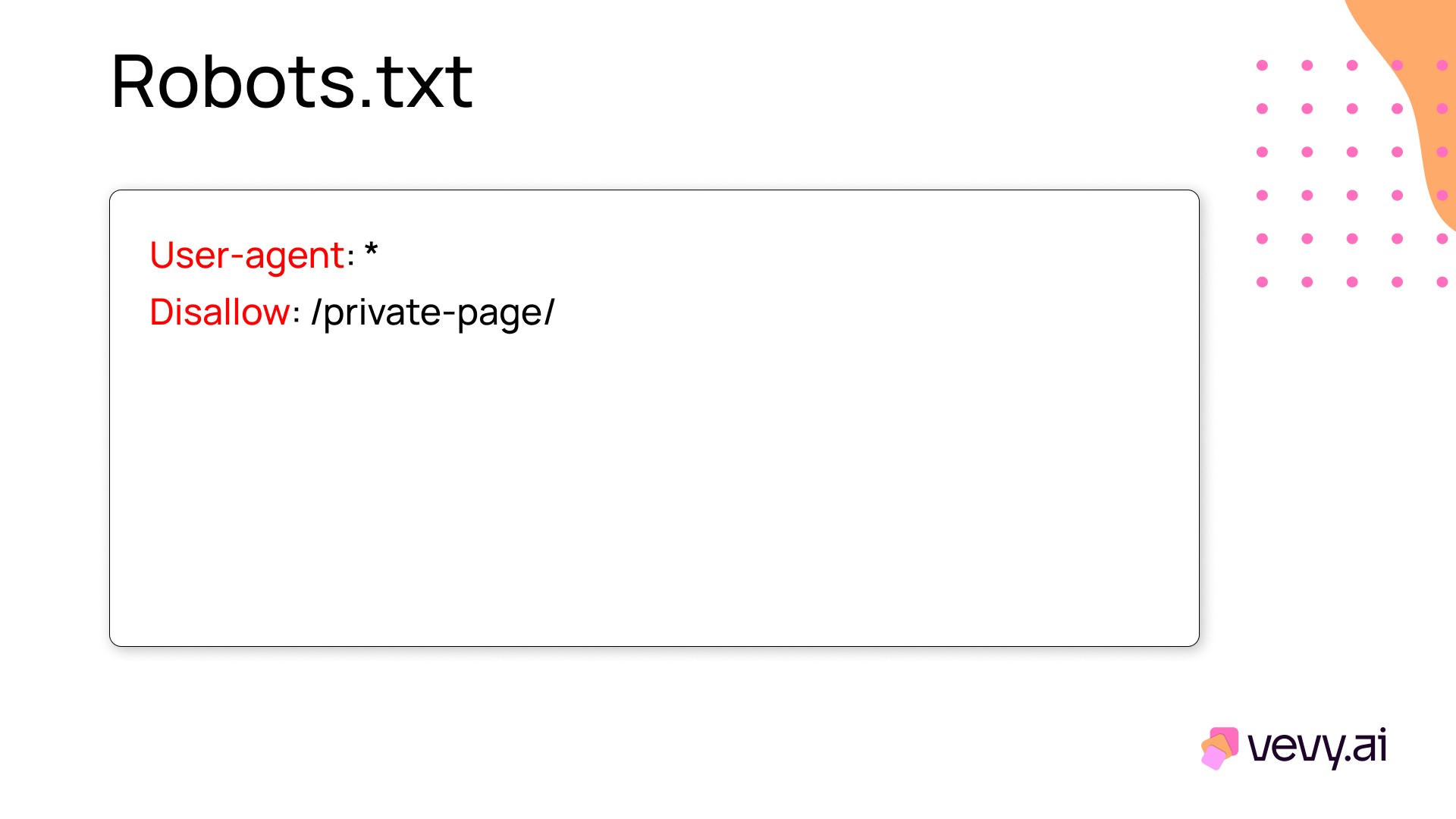
Robots.txt is a text file placed in the root directory of a website that gives instructions to web crawlers about which pages or sections of the site they can or cannot access. It helps manage how search engines interact with your website.
Robots.txt is particularly useful for controlling crawl budget by preventing crawlers from wasting time on irrelevant or duplicate pages, such as admin panels, filtered URLs, or staging environments. However, it doesn’t guarantee that these pages won’t be indexed if they’re linked elsewhere. For more precise control, you can use X-Robots-Tag or meta robots directives.
A properly configured robots.txt file complements good website architecture by guiding crawlers to focus on valuable content while ignoring less important sections. It also supports a clean URL structure, ensuring that search engines prioritize the most relevant pages.
Robots.txt can also prevent index bloat by blocking access to low-value or unnecessary pages. For example, it’s common to disallow crawling of search result pages or duplicate category URLs.