X-robots tags
What is X-Rotobs-Tag?
The X-Robots-Tag is an HTTP response header that controls how search engine crawlers interact with your content. Unlike robots.txt (which blocks crawling) or meta robots tags (HTML-based instructions), this header gives server-level control over indexing behavior. Think of it as a traffic light for web crawlers - it tells Googlebot exactly which pages to process and how. [Google Search Central].
The X-Robots-Tag is especially useful for controlling when you need to:
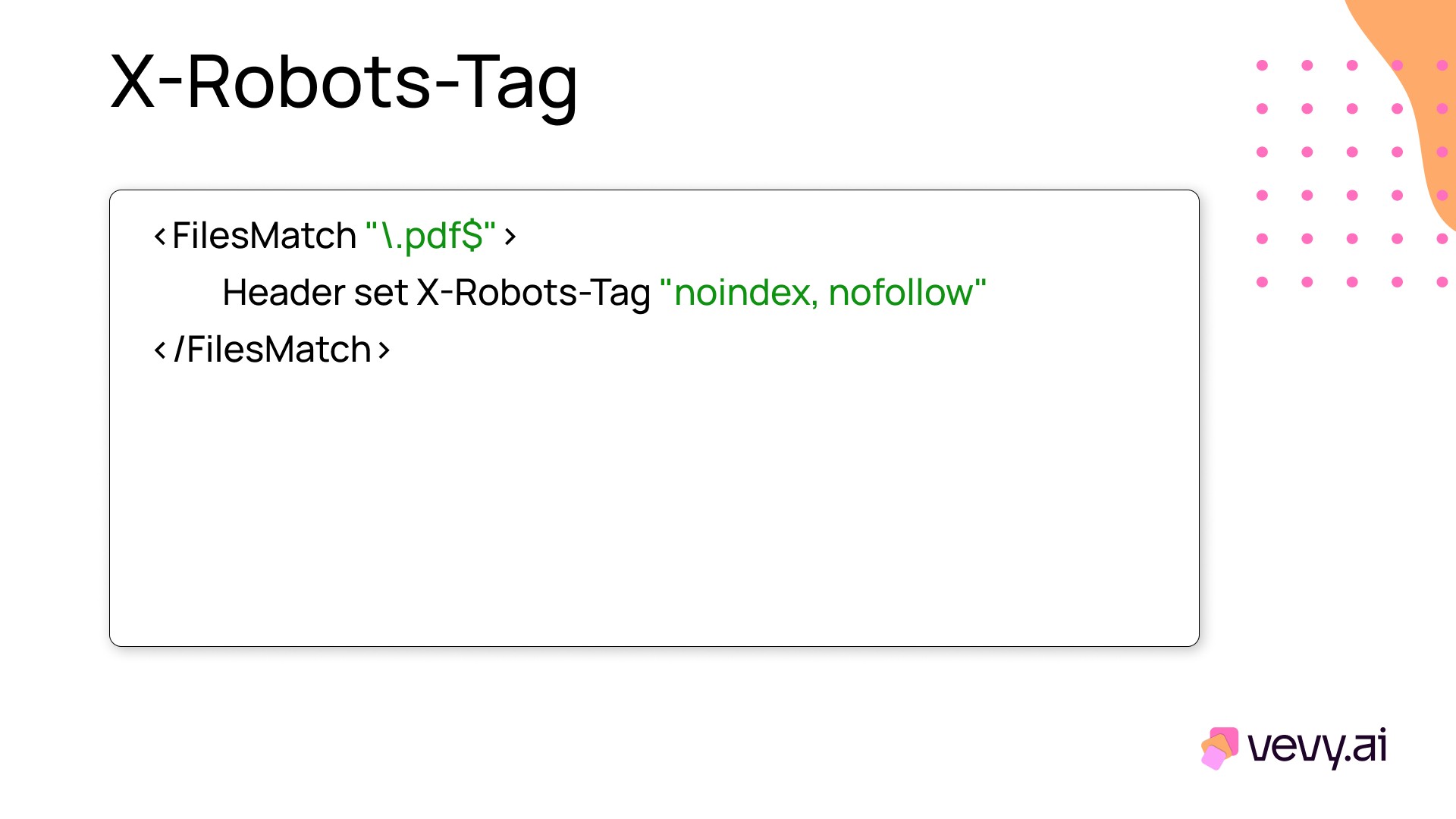
Block non-HTML files (PDFs, images)
Apply indexing rules at scale
Prevent index bloat from duplicate content
How to check x-robots-tag?
To see if a page has an X-Robots-Tag set up, try these easy methods:
1. Use Chrome Developer tools
Right-click on the webpage and pick “Inspect.”
Go to the “Network” tab.
Hit F5 to refresh the page. You'll see a list of files loading.
Click on the top file (usually the name of the webpage), then look at the “Headers” section.
In the headers, look for “X-Robots-Tag.”
2. Use cURL on the command line
Open your Command Prompt or Terminal and enter:
Change the URL to your file link. Look for a line in the result that says “X-Robots-Tag.”
3. Use online tools
There are online tools that check X-Robots-Tags. Just search “X-Robots-Tag checker” and use a trusted site. Enter your URL to see the tag information.
4. Check your server files
If you can access your server, check the .htaccess (for Apache) or nginx.conf (for Nginx) files for X-Robots-Tag rules. But be careful—changing these files can affect your site.
5. Use SEO tools for big sites
SEO tools like Screaming Frog can check X-Robots-Tags across many pages. Run a site crawl to see tag data for all your pages.
X-Robots-Tag directives
Some common directives used in X-Robots-Tags include:
all: Allows all search engine indexing and behavior (first must remove it).
none: Equivalent to noindex, nofollow, nosnippet, noarchive, and notranslate all together.
index: Index the page/file.
noindex: Don't index the page/file.
nofollow: Don't follow links on the page or file.
nosnippet: Prevents a text snippet from being shown in search results.
noarchive: Stops cached links from appearing in search results.
unavailable_after: A date after which the page should not be shown in search results.